What is a data scientist? What makes for a good (or great!) data scientist? It’s been challenging enough to determine what a data scientist really is (several people have proposed ways to look at this). The Guardian (a UK publication) said, however, that a true data scientist is as “rare as a unicorn”.
I believe that the data scientist “unicorn” is hidden right in front of our faces; the purpose of this post is to help you find it. First, we’ll take a look at some models, and then I’ll present my version of what a data scientist is (and how this person can become “great”).
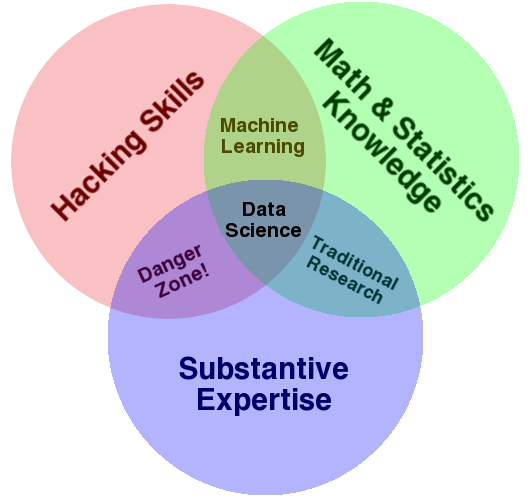
#1 Drew Conway’s popular “Data Science Venn Diagram” — created in 2010 — characterizes the data scientist as a person with some combination of skills and expertise in three categories (and preferably, depth in all of them): 1) Hacking, 2) Math and Statistics, and 3) Substantive Expertise (also called “domain knowledge”).
Later, he added that there was a critical missing element in the diagram: that effective storytelling with data is fundamental. The real value-add, he says, is being able to construct actionable knowledge that facilitates effective decision making. How to get the “actionable” part? Be able to communicate well with the people who have the responsibility and authority to act.
“To me, data plus math and statistics only gets you machine learning, which is great if that is what you are interested in, but not if you are doing data science. Science is about discovery and building knowledge, which requires some motivating questions about the world and hypotheses that can be brought to data and tested with statistical methods. On the flip-side, substantive expertise plus math and statistics knowledge is where most traditional researcher falls. Doctoral level researchers spend most of their time acquiring expertise in these areas, but very little time learning about technology. Part of this is the culture of academia, which does not reward researchers for understanding technology. That said, I have met many young academics and graduate students that are eager to bucking that tradition.” — Drew Conway, March 26, 2013
#2 In 2013, Harlan Harris (along with his two colleagues, Sean Patrick Murphy and Marck Vaisman) published a fantastic study where they surveyed approximately 250 professionals who self-identified with the “data science” label. Each person was asked to rank their proficiency in each of 22 skills (for example, Back-End Programming, Machine Learning, and Unstructured Data). Using clustering, they identified four distinct “personality types” among data scientists:
- Data Businesspeople who are most focused on the information itself and how it is applied to business decisions. (These people were least likely to identify with the “data scientist” label.)
- Data Creatives, the hackers with the broadest experience “from extracting data, to integrating and layering it, to performing statistical or other advanced analyses, to creating compelling visualizations and interpretations, to building tools to make the analysis scalable and broadly applicable.” They are chameleons who can shapeshift from one role into another as necessary (although they may not be extremely deep in any of the topic areas).
- Data Developers, the wizards of the technical aspects of data management (accessing it, moving it around, archiving it, curating it), and
- Data Researchers, those deeply familiar with the mathematical and statistical underpinnings of the work, who can develop new techniques as necessary (in addition to correctly selecting from available techniques).
As a manager, you might try to cut corners by hiring all Data Creatives(*). But then, you won’t benefit from the ultra-awareness that theorists provide. They can help you avoid choosing techniques that are inappropriate, if (say) your data violates the assumptions of the methods. This is a big deal! You can generate completely bogus conclusions by using the wrong tool for the job. You would not benefit from the stress relief that the Data Developers will provide to the rest of the data science team. You would not benefit from the deep domain knowledge that the Data Businessperson can provide… that critical tacit and explicit knowledge that can save you from making a potentially disastrous decision.
Although most analysts and researchers who do screw up very innocently screw up their analyses by stumbling into misuses of statistical techniques, some unscrupulous folks might mislead other on purpose; although an extreme case, see I Fooled Millions Into Thinking Chocolate Helps Weight Loss.
Their complete results are available as a 30-page report (available in print or on Kindle).
#3 The Guardian is, in my opinion, a little more rooted in realistic expectations:
“The data scientist’s skills – advanced analytics, data integration, software development, creativity, good communications skills and business acumen – often already exist in an organisation. Just not in a single person… likely to be spread over different roles, such as statisticians, bio-chemists, programmers, computer scientists and business analysts. And they’re easier to find and hire than data scientists.”
They cite British Airways as an exemplar:
“[British Airways] believes that data scientists are more effective and bring more value to the business when they work within teams. Innovation has usually been found to occur within team environments where there are multiple skills, rather than because someone working in isolation has a brilliant idea, as often portrayed in TV dramas.”
Their position is you can’t get all those skills in one person, so don’t look for it. Just yesterday I realized that if I learn one new amazing thing in R every single day of my life, by the time I die, I will probably be an expert in about 2% of the package (assuming it’s still around).
#4 Others have chimed in on this question and provided outlines of skill sets, such as:
- “Six Qualities of a Great Data Scientist“: statistical thinking, technical acumen, multi-modal communication skills, curiosity, creativity, grit
- The Udacity blog: basic tools (R, Python), software engineering, statistics, machine learning, multivariate calculus, linear algebra, data munging, data visualization and communication, and the ultimately nebulous “thinking like a data scientist”
- IBM: “part analyst, part artist” skilled in “computer science and applications, modeling, statistics, analytics and math… [and] strong business acumen, coupled with the ability to communicate findings to both business and IT leaders in a way that can influence how an organization approaches a business challenge.”
- SAS: “a new breed of analytical data expert who have the technical skills to solve complex problems – and the curiosity to explore what problems need to be solved. They’re part mathematician, part computer scientist and part trend-spotter.” (Doesn’t that sound exciting?)
- DataJobs.Com: well, these guys just took Drew Conway’s Venn diagram and relabeled it.
#5 My Answer to “What is a Data Scientist?”: A data scientist is a sociotechnical boundary spanner who helps convert data and information into actionable knowledge.
Based on all of the perspectives above, I’d like to add that the data scientist must have an awareness of the context of the problems being solved: social, cultural, economic, political, and technological. Who are the stakeholders? What’s important to them? How are they likely to respond to the actions we take in response to the new knowledge data science brings our way? What’s best for everyone involved so that we can achieve sustainability and the effective use of our resources? And what’s with the word “helps” in the definition above? This is intended to reflect that in my opinion, a single person can’t address the needs of a complex data science challenge. We need each other to be “great” at it.
A data scientist is someone who can effectively span the boundaries between
1) understanding social+ context,
2) correctly selecting and applying techniques from math and statistics,
3) leveraging hacking skills wherever necessary,
4) applying domain knowledge, and
5) creating compelling and actionable stories and connections that help decision-makers achieve their goals. This person has a depth of knowledge and technical expertise in at least one of these five areas, and a high level of familiarity with each of the other areas (commensurate with Harris’ T-model). They are able to work productively within a small team whose deep skills span all five areas.
It’s data-driven decision making embedded in a rich social, cultural, economic, political, and technological context… where the challenges may be complex, and the stakes (and ultimately, the benefits) may be high.
(*) Disclosure: I am a Data Creative!
(**)Quality professionals (like Six Sigma Black Belts) have been doing this for decades. How can we enhance, expand, and leverage our skills to address the growing need for data scientists?







Leave a Reply