The Central Limit Theorem (CLT), and the concept of the sampling distribution, are critical for understanding why statistical inference works. There are at least a handful of problems that require you to invoke the Central Limit Theorem on every ASQ Certified Six Sigma Black Belt (CSSBB) exam. The CLT says that if you take many repeated samples from a population, and calculate the averages or sum of each one, the collection of those averages will be normally distributed… and it doesn’t matter what the shape of the source distribution is! (Caveat: so long as the data comes from a distribution with finite variance… so that means the Cauchy distribution doesn’t count.)
I wrote some R code to help illustrate this principle for my students. This code allows you to choose a sample size (n), a source distribution, and parameters for that source distribution, and generate a plot of the sampling distributions of the mean, sum, and variance. (Note: the sampling distribution for the variance is a Chi-square distribution — if your source distribution is normal!)
sdm.sim <- function(n,src.dist=NULL,param1=NULL,param2=NULL) {
r <- 10000 # Number of replications/samples - DO NOT ADJUST
# This produces a matrix of observations with
# n columns and r rows. Each row is one sample:
my.samples <- switch(src.dist,
"E" = matrix(rexp(n*r,param1),r),
"N" = matrix(rnorm(n*r,param1,param2),r),
"U" = matrix(runif(n*r,param1,param2),r),
"P" = matrix(rpois(n*r,param1),r),
"B" = matrix(rbinom(n*r,param1,param2),r),
"G" = matrix(rgamma(n*r,param1,param2),r),
"X" = matrix(rchisq(n*r,param1),r),
"T" = matrix(rt(n*r,param1),r))
all.sample.sums <- apply(my.samples,1,sum)
all.sample.means <- apply(my.samples,1,mean)
all.sample.vars <- apply(my.samples,1,var)
par(mfrow=c(2,2))
hist(my.samples[1,],col="gray",main="Distribution of One Sample")
hist(all.sample.sums,col="gray",main="Sampling Distribution\nof
the Sum")
hist(all.sample.means,col="gray",main="Sampling Distribution\nof the Mean")
hist(all.sample.vars,col="gray",main="Sampling Distribution\nof
the Variance")
}
There are 8 population distributions to choose from: exponential (E), normal (N), uniform (U), Poisson (P), binomial (B), gamma (G), Chi-Square (X), and the Student’s t distribution (T). Note also that you have to provide either one or two parameters, depending upon what distribution you are selecting. For example, a normal distribution requires that you specify the mean and standard deviation to describe where it’s centered, and how fat or thin it is (that’s two parameters). A Chi-square distribution requires that you specify the degrees of freedom (that’s only one parameter). You can find out exactly what distributions require what parameters by going here: http://en.wikibooks.org/wiki/R_Programming/Probability_Distributions.
Here is an example that draws from an exponential distribution with a mean of 1/1 (you specify the number you want in the denominator of the mean):
sdm.sim(50,src.dist="E",param1=1)
The code above produces this sequence of plots:
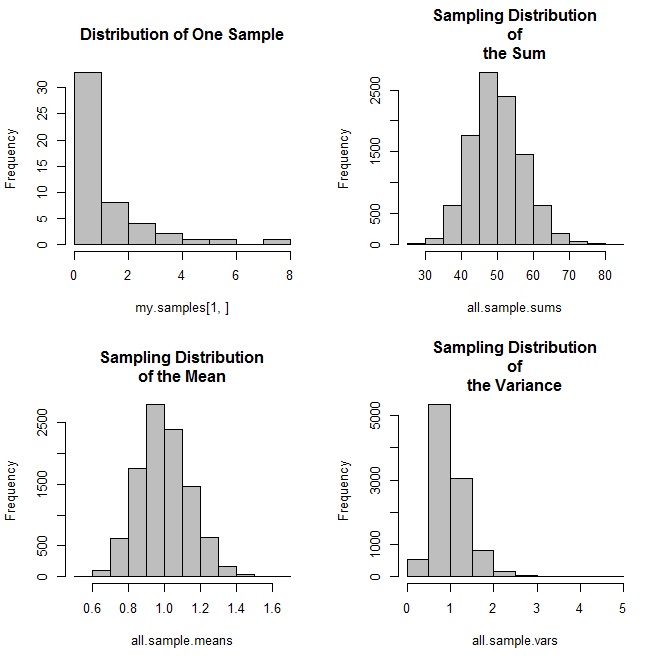
You aren’t allowed to change the number of replications in this simulation because of the nature of the sampling distribution: it’s a theoretical model that describes the distribution of statistics from an infinite number of samples. As a result, if you increase the number of replications, you’ll see the mean of the sampling distribution bounce around until it converges on the mean of the population. This is just an artifact of the simulation process: it’s not a characteristic of the sampling distribution, because to be a sampling distribution, you’ve got to have an infinite number of samples. Watkins et al. have a great description of this effect that all statistics instructors should be aware of. I chose 10,000 for the number of replications because 1) it’s close enough to infinity to ensure that the mean of the sampling distribution is the same as the mean of the population, but 2) it’s far enough away from infinity to not crash your computer, even if you only have 4GB or 8GB of memory.
Here are some more examples to try. You can see that as you increase your sample size (n), the shapes of the sampling distributions become more and more normal, and the variance decreases, constraining your estimates of the population parameters more and more.
sdm.sim(10,src.dist="E",1) sdm.sim(50,src.dist="E",1) sdm.sim(100,src.dist="E",1) sdm.sim(10,src.dist="X",14) sdm.sim(50,src.dist="X",14) sdm.sim(100,src.dist="X",14) sdm.sim(10,src.dist="N",param1=20,param2=3) sdm.sim(50,src.dist="N",param1=20,param2=3) sdm.sim(100,src.dist="N",param1=20,param2=3) sdm.sim(10,src.dist="G",param1=5,param2=5) sdm.sim(50,src.dist="G",param1=5,param2=5) sdm.sim(100,src.dist="G",param1=5,param2=5)








Leave a Reply