
So yesterday, I set up an #AmazonGiveaway for my new R book at https://giveaway.amazon.com/p/ea32d421d8d7672d — but I had my 10 year old input the number that will determine every nth person who gets the printed copy delivered to them, so that I’d be surprised too when it happened. Well I got surprised today, because nothing’s happened yet… he must have set the number pretty high. I’m a little impatient, so I decided that today I’d like to randomly sample my most recent 100 Twitter followers and send 3 eBooks to whoever comes up.
Turns out, it was pretty simple once I found the right documentation. This was the first time I’ve successfully accessed information from Twitter within R; when I tried other times, the documentation I encountered was problematic and the authentication never worked. But I finally converged on excellent documentation which helped to solve my problem at http://geoffjentry.hexdump.org/twitteR.pdf.
First, I went to https://apps.twitter.com/app/new and set up an application called “random-new-followers”. I think the choice of name is totally arbitrary… Twitter just wants a way to track who’s using their API and how it’s being used. I gave this form my name and web site URL as well. Next, I went to the “Keys and Access Tokens” tab. I had to click the “Create Access Token” button at the bottom. Once I did, I had 4 different access keys to work with, each of which looks like an unwieldy string of numbers and letters and has one of the following four names:
- Consumer Key (API Key)
- Consumer Secret (API Secret)
- Access Token
- Access Token Secret
Then I went into my R console. First, I wanted to make sure I had the most recent copy of the httr and twitteR packages. After using .libPaths() to find out where my R packages are installed, I went into those directories and blew away the old folders containing httr and twitteR. Then I went into R and re-installed the two packages:
> install.packages("httr")
> library(httr)
> install.packages("twitteR")
> library(twitteR)
At this point, authenticating and getting access to the Twitter data was pretty straightforward:
setup_twitter_oauth("Consumer Key", "Consumer Secret",access_token="Access Token", access_secret="Access Token Secret")
(When YOU use the above code, be sure to plug in the long, unwieldy number-and-letter combinations you saw on your “Keys and Access Tokens” tab. They are unique to you… and this is what unlocks twitteR so you can get real data!) Next, you can specify the user whose information you’d like to obtain, and using getFollowers() you can find out information about their followers:
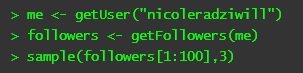
Notice that I only wanted to randomly sample from my most recent 100 followers, hence the [1:100]. The names that pop up in quotation marks are my random sample of followers. (If you wanted to sample from all your Twitter followers, just leave out the [1:100].) After I got my three random followers, I checked out their Twitter pages. The bad news? I think they are all bots 😦
(So then I filtered out anyone who had “811” or “#AmazonGiveaway” in their recent Tweets.)
There is a lot more information that’s obtained when you try getUser() from the twitteR package. If you’ve gotten this far, check out all of the interesting information (and methods) that are contained in the results by typing this:
> str(me)








Leave a Reply